Table of Contents
Geekmarks
Hi everyone! So I wrote a new bookmarking service: Geekmarks, it's free and open-source (GitHub).
We already have a lot of bookmarking services, so why bother writing another one? Good question.
Rationale
In short, I want my bookmarking service:
- To be very quick to use;
- To provide a way to organize my bookmarks in a powerful way.
I tried a lot of existing bookmarking services, and I wasn't satisfied by any of them, for a variety of reasons.
Let me elaborate on the organization part first. The simplest way to organize bookmarks is to introduce folders to group them. This still poses a well-known problem though: some bookmarks can logically belong to multiple folders. In order to address this issue, some services use tags: now we can tag a bookmark with more than one tag. So far so good.
Now, assume I have a generic tag programming, and a couple of more specific tags: python and c. I definitely want my bookmarking service to be smart enough to figure that if I tag some article with either python or c, it means programming as well; I don't want to add the tag programming manually every single time. So, what we need is a hierarchy of tags. Surprisingly enough, I failed to find a service which would support that.
This hierarchical tags thing was a major motivation for me to start Geekmarks.
Another important thing is that I want bookmarking service to be very quick to use. I don't want to go through these heavy user interfaces and look at all the eye candy. In my daily life I just want to either add a bookmark or find one, and I want to do that quickly: like, just a few keystrokes, and I'm done.
And last but not least, I love open-source. So, meet Geekmarks! A free, open-source, API-driven bookmarking service.
Overview
There's a backend (written in Go and PostgreSQL) which exposes a RESTful API, and various clients which talk to the backend.
Data storage
All the data is stored on the server; client does not store anything. Even when the user enters a tag name, and UI shows the autocomplete menu with matching tags, the menu contents are loaded from the server.
Of course, this has both advantages and disadvantages.
The good thing is that the arcitecthure is “clean”: clients are dumb, server is the one who does all the job. Among other things, this simplifies the process of writing new clients, and all the data is automatically synchronized between all user's clients with no extra effort.
Now let me consider disadvantages and argue why I still opted to use this design.
- Some users might have a strong opinion against storing their bookmarks (as well as any other data) on a third-party server; they want to control the data storage. This part is solved by the fact that everything in Geekmarks is open-source: one can easily deploy the backend to their own server, or even run it locally on the laptop; and adjust the backend URL in the client settings. Now, everything is under the user's control.
- Other users might be fine with storing bookmarks on a third-party sever, but they might be afraid of losing all their data if the service stops working for whatever reason. In order to address this issue, I'm going to implement import/export of all the account's data. So, one might write a short script with a single
curlcommand which fetches JSON data with all tags and bookmarks and saves it locally, and run this script regularly (via crontab or similar things). Now, the data is backed up, and if something bad happens with the server, the user can resort to deploying Geekmarks backend to their own server or locally, and import all the data there.
- One more possible claim is that the tool won't work offline. While this is true, it shouldn't be a major concern, because the whole point of Geekmarks is to store URLs, so even if you can get the previously saved URL offline, you'll anyway need the Internet connection in order to visit the webpage by this URL!
- And the last thing I can think of is that constantly accessing the server for this and that is slower than just storing everything locally. Of course it is slower, but it doesn't affect user experience too much: all the communication is going via the websocket, and, from my experience, the user rarely needs to wait more than 150ms (for me, it's usually less than 70ms actually).
Project status
Backend is thoroughly tested and is very stable. API will be also frozen soon.
Client implementation, however, is not in a particularly good shape: it's a Chrome extension, and it's only a proof of concept. It's just barely good enough: it provides all the features and it's completely usable, but it's written in probably not a very good manner, its appearance is kinda rough, etc.
My plan is to rewrite the client in Angular 2, or maybe React, and hopefully I'll be able to factor out the most part and reuse it for many kinds of clients: web interface, browser extensions, and mobile phone apps (via Native Script or React Native). But that will be a long story, since I'm not really a frontend guy, and I'll need to learn a lot.
Demo
After installing the Chrome extension, click on the “g” icon:
Log in (via Google account), and when it's done, menu will look as follows:
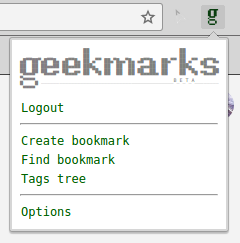
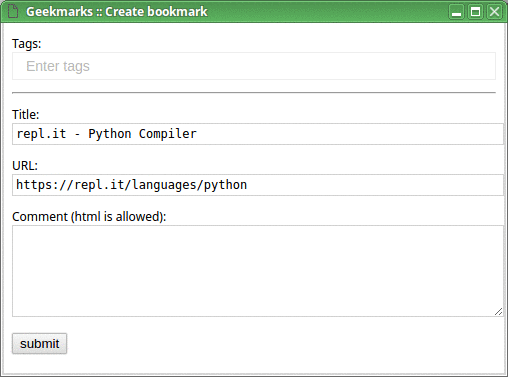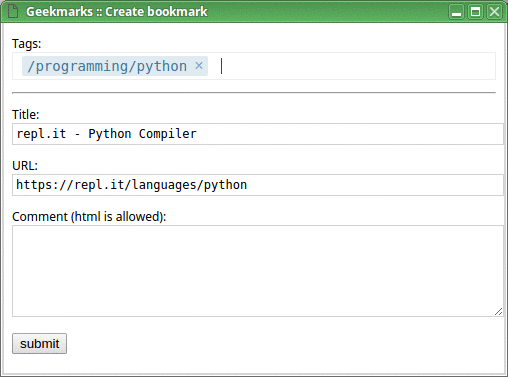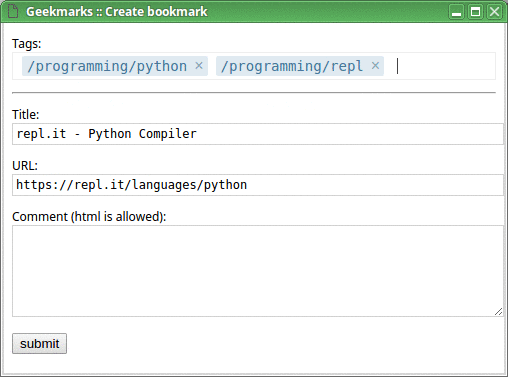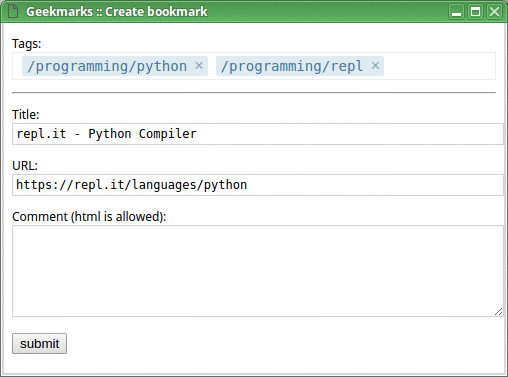
Now, on any page you want to bookmark, click “Create bookmark” from the menu (or use a hotkey; I personally use Shift+Ctrl+B), enter tags for your new bookmark, and save it. Tags which don't yet exist will be created on the fly.
When you do that for the first time, it might look as follows:

Later, when you have more tags, the process of adding a new bookmark will be faster, like this:
And this is how you find your bookmarks, after all (I use a Ctrl+B hotkey for that):
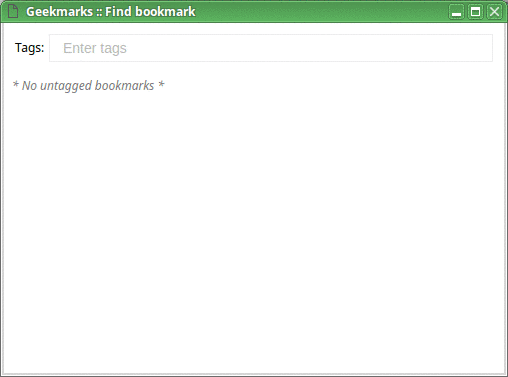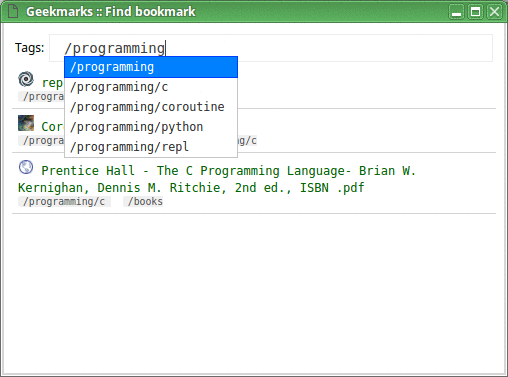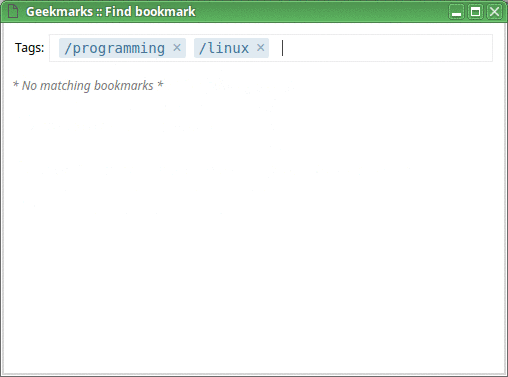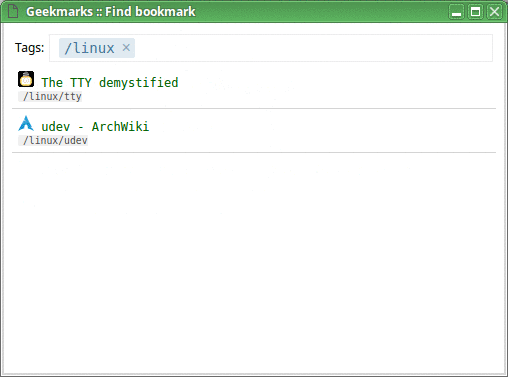
Tips
Untagged bookmarks
Being able to organize bookmarks with hierarchical tags is really nice, but sometimes I'm too busy and I don't want to think carefully about where to put my bookmark; instead, I just want to quickly add it somewhere, and postpone the proper tagging for later. This is supported: when one wants to add current page as an untagged bookmark, it's as easy as Ctrl+Shift+B, Enter (provided that the keyboard shortcut is Ctrl+Shift+B).
Next time, when “Find bookmark” dialog is opened, all untagged bookmarks are shown immediately, before the user enters any tag; so, the user won't forget to tag them properly later.
Tag aliases
When editing a tag, one can specify multiple comma-separated names, and all of them will refer to the same tag. It's convenient in many cases, e.g. go and golang, jobs and careers, etc.
Note on hierarchical tags
I really love the hierarchical tags idea, and as I said, it was a major motivation for me to start Geekmarks. However, one should not misuse it.
For example, it's perfectly fine to place golang under programming, because Go, indeed, always implies programming.
But consider the case when we want to store something about terminal emulators, and we want to be more specific: terminal emulators which work under Linux. It would be a bad idea to create a hierarchy like /terminal/linux, because linux, of course, does not necessarily imply terminal. If we go with this, then we'll eventually end up with a bunch of tags like /terminal/linux, /programming/linux, /whatever-else/linux; and when we type linux in the tags input field, we'll get multiple tags with the same name, and we won't be able to just get “everything related to Linux”.
Instead, /linux should be a standalone tag, and the URL which describes something about terminal emulator under Linux should be tagged with both /terminal and /linux.
So, the rule of thumb is: before placing a tag foo under bar, ask yourself: does foo always imply bar? If yes, then go on. If no, then foo should be a separate tag.
That said, if you're unsure about how to arrange your tags, don't worry too much about it, since you can easily move your tags around later, and your bookmarks will be retagged appropriately.
Plans
I don't really know when I'll be able to implement all of it, but nevertheless, this is what I'd like to have sooner or later:
- Firefox extension;
- Client for Android (and probably iOS);
- Authentication via something other than Google;
- Filter bookmarks not only by tags, but also by title/url;
- Export/Import of all the account's data;
- Add numeric “rating” to tags, and sort bookmarks accordingly to the rating of the tags it's tagged with.
Discussion
This is pretty cool. Just what I was looking for :D Will start migrating to it now!
Glad you liked, thanks for the comment! :)
This looks great! I badly need a working firefox front end though to be able to move over to this. Secondly, is it possible to make snapshots of the bookmarks for backups/history etc?
Thanks for the feedback!
Yeah I plan to implement a firefox extension as well, not sure how should I prioritize things though.
W.r.t. snapshots: as I indicated in the article, export/import is surely planned, and will be implemented rather soon: one will be able to write a script with basically a single
curlcommand which will fetch all the account's data and store locally. Then, this script can be executed via cron or similar things.is a bookmarklet out there?
Sorry, what exactly do you mean by bookmarklet?
https://de.wikipedia.org/wiki/Bookmarklet
Interesting idea. I decided to keep all my bookmarks and notes in a mind map. (https://github.com/nikitavoloboev/research).
I really like the format of it as I can have both tags and structure and everything is connected and public to the world.
Import from Pinboard would be greatly appreciated. Their support is unresponsive and the API is broken. Renaming of tags would also be very useful.
Thanks for the comment. Honestly, I've never heard of Pinboard before, so I can't say anything about it at the moment, I'll look into this.
Renaming of tags is surely possible: you can open tags tree, then mouseover your tag, and click the “edit” icon which will appear at the right side. You can change the name, or even specify multiple names (aliases).
I've been thinking about the same idea of “hierarchical tags” in the context of OS X's tags feature. I wonder if that just brings up the same problems as direct hierarchies, or if moving the hierarchy to the tag level fixes a lot of those problems.
To me, it does solve these problems: if I understand you correctly, the problem with direct hierarchy you're talking about is that the item might belong to many places. By tagging the item with a few tags, we effectively put the item in many places in the hierarchy. It's a kind of equivalent of (hard) links in the filesystem.
really like the concept of hierarchical tags (and open source which allows self hosting - even though I'm not intending to do so right now) Been using Pinboard so far - fairly similar - but would consider switching. Keep up the good work. UI looks definitely good enough for now. Firefox/mobile(android) access would be great
Thanks for the feedback.
It's actually weird that I missed pinboard before, but you mentioned that you would consider switching. Of course I'm curious to hear the reasons: what's about pinboard that you aren't satisfied with?
As to other clients, yeah, hopefully I'll get time for that.
This looks very good! But considering that it's free and it consumes your server-side resources, will it remain free?
Hi, thanks for the feedback!
I can't say 100% sure that my hosted server will remain free, but one of the good parts about open source thing is that people can self-host it. As I mentioned in the article, one could deploy it to their own server, or even locally to the laptop, and don't rely on my server.
The only missing piece to be implemented for it is export/import, and it definitely will be implemented: one can start with my server, and if later they decide to move to the self-hosted one, for whatever reason, they could export all the data from my server, then import to theirs, and that's it.
Geekmarks looks like a total copy of Shaarli: https://github.com/shaarli/shaarli/
As far as I know, there's no hierarchical tags in Shaarli. And one has to install it on their own server, whereas with Geekmarks one can, but does not have to.
I can't wait for the Swagger spec for your API!
A major feature for a bookmark service is to help to keep the bookmarks relevant: check availability, report 404s to the user, replace permanent redirects (301), detect duplicates and save the canonical one (rel=“canonical”).
Unfortunately, Swagger is too limited: firstly, it does not support multiple schemas for the request (which depend on query parameter,
shapein my case), and secondly, it does not support wildcard paths (e.g. in Geekmarks/api/tags,/api/tags/fooand/api/tags/foo/bar/bazare all valid paths).The former could be worked around (see https://github.com/OAI/OpenAPI-Specification/issues/146#issuecomment-117288707), the latter cannot, and it's even unclear if it will be supported in the future (see https://github.com/OAI/OpenAPI-Specification/issues/892).
Maybe I'll have to deviate from the spec and use modified version of swagger-ui… But I'm not sure if it's a good idea.
Done :) https://geekmarks.dmitryfrank.com/swagger/
Are the bookmarks encrypted server side ?
No.
Love it! Started putting in a load of bookmarks already. One improvement that would be amazing is if you could search generally and not just by tag.
Thanks for the feedback! Yes, as I mentioned in the Plans section, I want to implement bookmarks filtering not only by tags, but also by the title and/or URL.
Great stuff!
I look forward to it.
If you want any contributions I can help out!
Cheers
I was excited to find Geekmarks, but I'm looking for a way to re-organize a thousand existing bookmarks in Chrome. Are you still planning an import function, or is there something in the extension that I'm missing? Thanks for making this open source.
PS Loved your nature photos, too. I'm not sure if you're in Russia, but they reminded me of a summer spent there in the countryside in college.
Allison, thanks for the feedback!
I do plan to implement the import/export, but I'm afraid we might misunderstand each other here: I wanted to implement import/export in a geekmarks-specific format; the use case for it is to backup all the bookmarks from the “cloud” to your local machine, and being able to restore it back, probably to another instance of geemarks server. So, importing bookmarks from Chrome is a different thing; I agree it can be useful, but not really sure I'll manage to implement it any time soon. However, with the planned import/export feature in place, maybe it will turn out to be relatively easy to add support for Chrome format too, so let's see.
And I'm glad you liked the nature photos :) Yeah I used to live in Russia, and those photos are from there.
Thanks for the reply, Dmitry!
Looks quite nice.
Sadly not quite for me :(
I'd love a simple way to host a local server on windows.
Hi. When You plan release for FF extension?
Nice idea.
Greetings Dimitri
Just stumbled over GeekMarks. looks very interesting what you have built here. As mentioned by Olivier keeping bookmarks relevant is an important feature, presenting the collected bookmarks could also be a nice eye candy and the demo site is not so empty.
I'm a big fan of self-hosting, so a docker image ('m aware that one can build the image by them self) and a docker-compose that would enable one to get it quickly up and running without installing go would ease the start.
Thank you for your effort.
Hi. I have a ton of bookmarks in my browser and it is already unmanageable. Wanted to build my own bookmark manager and started thinking/searching about this and that is how I stumbled upon GeekMarks.
My idea was to have a hierarchical directory structure + tags. Your's (hierarchical tags) is definitely superior. I was also unable to make up my mind about the storage - whether to do it on the server or on the browser and the API design and what you have said on this makes perfect sense. Thank you for mentioning your rationale behind these decisions.
Will definitely try GeekMarks!
Awesome, thanks for the feedback!
As to the hierarchical tags, just fyi: as time proves, I'm not 100% satisfied with it; I want it to be even more versatile. The main thing which I dislike currently is: each tag can only have one parent. I step into this almost every time I make a new bookmark: e.g. the tag
vimshould imply botheditorandprogramming;routershould imply bothnetworkandhardware, etc etc. This is what I miss the most.That'd require a major redesign though, so I'm afraid it won't happen soon.
I'd like to give it a try.
How can we share a link? Could you add an highlighting and annotating tool? And way to save a copy of the page on the disk? (because links disappear with time). Tagpacker has an AI with autotagging, it's very useful when I'm too busy to find a tag.
Nothing from that is planned for near future, sorry.
Hi, I just stumbled upon Geekmark while searching for a self-hostable replacement for Favattic which served me well but recently started to have some serious problems. The hierarchical tags are ingenious!
One question though: I am trying to combine a PC, a Mac, a Raspi (ie. Linux), an Android and an iOS device here (yes, more or less the worst case ). The first three are no problem thanks to your Chrome plugin which also works for Vivaldi, but the mobiles seem to be. While Favattic did not provide plugin support for those devices as well, it did have an acceptable web interface you could login to and use instead to open links - not too comfortable, but good enough.
). The first three are no problem thanks to your Chrome plugin which also works for Vivaldi, but the mobiles seem to be. While Favattic did not provide plugin support for those devices as well, it did have an acceptable web interface you could login to and use instead to open links - not too comfortable, but good enough.
If I did not overlook it in the documentation, Geekmarks does not have that (yet?), correct?
Kind regards!
Hi Florian, yeah that's right, unfortunately Geekmarks doesn't yet have mobile apps. The android app is something I'd like to have at some point, but no ETA at the moment.
Thnaks for the information Dmitry. The question was more about whether a web interface for Geekmark is possible though that could be used to access the saved bookmarks with any browser and therefore would work as a (somewhat limited) replacement for any unsupported device. As far as I understand what I read, Geekmark does not have that yet, correct?
That's right, as of now, there is no web ui either. :(
Is there anyway to bulk export items out of Geekmarks?
I wanted to do that for ages, but never got enough time. There is an old WIP branch
export(pushed to the github), but it's far from done.Thanks for this! Is there a plan to develop this for Android in the near future? Thanks
Hi there. Sadly, no short-term plans for Android client development yet.