Table of Contents
How I ended up writing a new real-time kernel
You're reading the original article in English. You can as well read the translation in Russian.
I work with embedded stuff for several years: our company develops and manufactures car trip computers, battery chargers, and other car-related electronic devices.

The processors used for our designs are primarily 16- and 32-bit Microchip MCUs, with RAM from 8 to 32 KB, and ROM from 128 to 512 KB, without any kind of MMU. Sometimes, there are even more modest 8-bit chips.
So, it's clear that we have no chance to use any kind of Linux kernel in our products. Some people even write firmware for microcontrollers without any kind of OS, but I prefer not to be one of them, as long as the hardware allows me to run an OS. So, we need for some kind of RTOS (Real-Time Operating System).
When we were moving from 8-bit chips to more powerful 16-bit ones, my colleagues, which were more experienced than me, suggested preemptive RTOS TNKernel. So, this is the RTOS I was using for about 2 years for different projects.
Not that I was very happy with it: for example, it doesn't have timers. And it doesn't allow threads to wait for messages from multiple queues. And it does not have stack overflow detection: this one really annoyed me. But it worked, so I was keeping using it.
How does preemptive OS work
Just to make sure we understand each other, I'm going to make a quick overview of how does preemptive OS work, in general. I apologize if things I'm saying are too trivial for you.
Running multiple threads
Processors are “single-threaded”: they can only execute single instruction at a time (Well, of course, there are modern multi-core processors, but this is a different story). In order to run multiple threads on a single-core processor, we effectively need to periodically switch between threads, so that the user has a feeling that threads run in parallel.
This is what an operating system is for, in the first place: it switches between threads. How does it do that?
Processor has set of registers. Since processors are single-threaded, this set of registers belongs to just a single thread. For example, when you calculate a sum of two numbers:
//-- assume we have two ints: a and b int c = a + b;
What is actually going on is something like the following (of course, it highly depends on exact MCU type, but the general idea is the same) :
# the MIPS disassembly: LW V0, -32744(GP) # value of ''a'' is loaded from RAM to register V0 LW V1, -32740(GP) # value of ''b'' is loaded from RAM to register V1 ADDU V0, V1, V0 # values of two registers are summed up, and the result is saved into register V0 SW V0, -32496(GP) # value of register V0 is stored into RAM (where the variable c is located)
4 actions there. And since in preemptive OS one thread may preempt another one in virtually any moment of time, of course it could happen in between of this sequence. So, imagine some other thread preempts the current one after both registers V0 and V1 are filled with values. The new thread has its own business, and, therefore, its own utililization of the registers. Of course, two threads should not interfere with each other, so, when the current thread will be resumed, it should have exactly the same values of these registers as they were.
It leads us to the fact that when switching from thread A to thread B, first of all we need to store all registers of thread A somewhere, then restore registers of thread B from somewhere. And only then thread B resumes execution, and continues to work just like nothing special happened.
So, more accurate diagram of the system operation would look as follows:
When we need to switch from one thread to another, the kernel gains control, performs necessary housekeeping (at least, saves and restores register values), and then control is transferred to the next thread to run.
So, where exactly is the “somewhere”, in which register values are saved for each thread? Quite often, this is the thread's stack.
Thread's stack
In modern operating systems, (user's) thread stacks grow dynamically on demand thanks to processor's MMU: the more stack space the thread needs, the more it gets (if the kernel allows). But MCUs I work with don't have luxuries like that: all RAM is mapped statically to the address space. So, each thread receives its own piece of RAM that is used for stack, and if the thread uses more stack than that, it leads to memory corruption and subtle bugs. Effectively, stack space for each thread is just a plain byte array.
So, when we decide how much stack to allocate for each thread, we just estimate how much it might need. For example, if this is a GUI thread with deeply nested calls, it may need several kilobytes, but if it's a little thread which listens for buttons pressed by user, 512 bytes might be enough.
So, let's assume we have three threads, and their stack consumption is as follows:

As I mentioned, register values for each thread are saved in the thread's stack. The set of thread's register values is called a thread's “context”. The following chart shows that (active thread is marked with an asterisk):
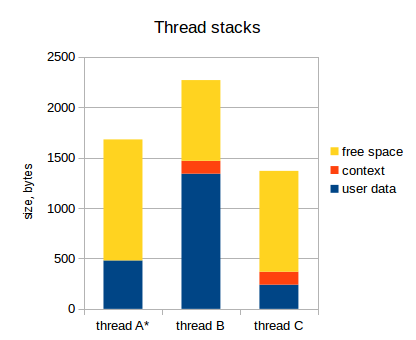
Notice that active thread (thread A) does not have its context saved on the stack. The stack pointer points at the top of user data of thread A, and current processor's registers are dedicated to the thread A (well, actually there might be some special kernel-related registers, but this is out of interest right now)
When the kernel decides to switch control to the thread B, it does the following:
- Save all register values to stack (effectively, to the top of stack of thread A);
- Switch stack pointer to the top of stack of thread B;
- Restore all register values from stack (effectively, from the top of stack of thread B);
After that, we have the following:
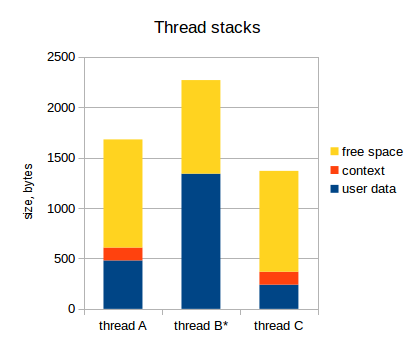
And thread B goes on with its business.
Interrupts
We haven't yet touched upon very important topic: interrupts.
Interrupt condition is when currently executing thread is paused, processor does something else for some time (handles an interrupt), and then goes back. Interrupt can be triggered in any moment of time, and we should be prepared to handle it.
In embedded development, MCUs typically have quite a lot of on-board peripheral: timers, various data translation units (UART, SPI, CAN, etc). All of them are typically able to trigger interrupts when something important happens: for example, UART peripheral may trigger an interrupt when new byte is received, so that the software can store received byte somewhere. Timer peripheral triggers an interrupt when timer overflows, so that software can perform some periodical things, etc.
The interrupt handler is called ISR (Interrupt Service Routine).
Interrupts may have different priorities: for example, if some low-priority interrupt is triggered, the currently executing thread is paused, and the ISR gains control. And then, if some high-priority interrupt is triggered, then the currently executing ISR is, again, paused, and a new ISR for said high-priority interrupt runs. Obviously, when it finishes, control returns to the first ISR, and when it finishes as well, the interrupted thread is resumed.
There are short periods of time when we can't guarantee things to work correctly if interrupt happens: for example, when we handle some data that can be changed by an ISR: if we handle it in several steps, and interrupt is triggered in between of these steps and changes the data, then resulting data will be inconsistent, which can easily lead to disaster.
These short periods of time are called “critical sections”: when we enter it, we just disable interrupts globally. When we exit it, we enable interrupts back. So, if some interrupt is triggered during critical section, it will actually interrupt execution only when interrupts will be re-enabled.
The very interesting question is: where to store ISR's stack data?
Interrupt's stack
In general, we have two options:
- Use stack of the thread being interrupted;
- Use separate stack space for interrupts.
If we use stack of the thread being interrupted, it looks as follows (in the diagram below, the thread B is interrupted) :
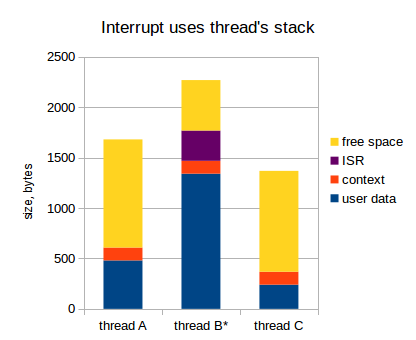
When interrupt is triggered:
- Context of the current thread gets saved to the thread's stack (because after ISR is finished, we may want to switch to other thread, so, context of the current thread is already saved);
- ISR does its business;
- If we need to switch to different thread, do it (at least, switch stack pointer)
- Context of the thread is restored from the stack;
- Thread continues to operate.
It may work rather fast, but in the context of embedded development, when we have very limited resources, this approach has one serious drawback. Can you spot which one?
Remember that interrupt can happen in any time, so obviously we don't know which thread will be active when interrupt happens. So, when deciding how much stack space each thread needs, we must assume that all existing interrupts can happen in this thread, and that interrupts with different priorities may nest. This may pretty much bump your stack sizes by 1 KB or even more (depending on your application, of course). Take, for example, that our application has 7 threads, it results in 7 KB. If our MCU has only 32 KB of RAM (this is quite a lot for MCU, by the way), this is more than 20%! Oh shi~.
So, to summarize, the stack of each thread should be able to hold the following things:
- Thread's own data;
- Thread's context;
- Data for worse-case ISR execution.
Ok, going on to the next option, we use separate stack space for all interrupts:
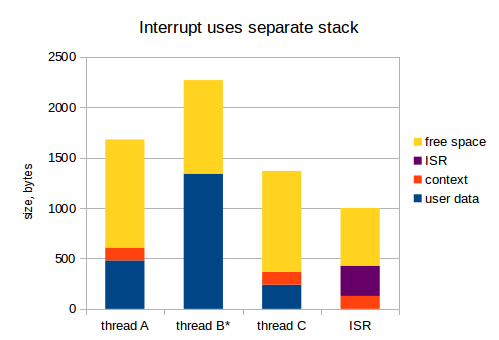
This way, the 1 KB for ISRs from previous example should be allocated just once. I consider this as a superior approach: in embedded world, RAM is a very expensive resource.
Now, with this brief overview of the RTOS operation, let's move on.
TNKernel
As I said in the beginning, we were using TNKernel for 16- and 32-bit MCUs.
Unfortunately, TNKernel port for Microchip MCUs by Alex Borisov uses the approach when interrupts use thread's stack. This wastes my RAM and does not make me very happy, but otherwise TNKernel looked good: it is compact and fast, so I was keeping using it. Until the day X, when I was surprised to find out that things are actually much worse.
TNKernel for PIC32 fails
I was working on regular project: a device that analyses signal at the ignition spark, and allows user to observe timings and voltages. Since the signal changes quickly, we need to make ADC measurement rather often: once per 1 or 2 microseconds.
The processor used for this device is PIC32: a Microchip's processor with the MIPS core.
It shouldn't be too difficult, but one day I started getting problems: sometimes, when device starts measuring, program was crashed in a weird way. Must be some memory corruption, and it made me very sad, because hunting a bug with memory corruptions can be extremely tough: remember that there's no MMU, all RAM is available to all threads in the system, so if one thread goes wild and corrupts some memory in other thread, the problem might arise somewhere very far from where the actual error is.
I already mentioned that TNKernel has no software stack overflow control, so, when we have some memory corruption, the first thing to check is whether stack of some thread is overflown. When thread is created, its stack is initialized with some value (in TNKernel for PIC32, it's just 0xffffffff), so we can easily check whether the top of the stack space is “dirty”. So I looked there, and yes, stack of the idle thread is clearly overflown:
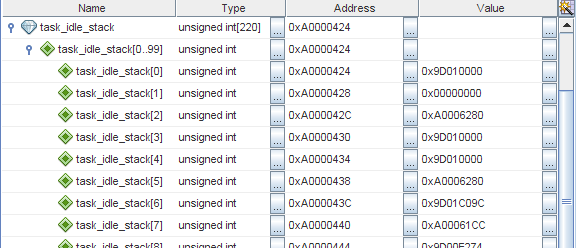
On MIPS, stack grows down, so, task_idle_stack[0] is the latest available stack word for the idle task.
Okay, at least it's quite something. But the thing is that the stack for this thread is allocated with huge extra space: when device operates normally, only about 300 from 880 bytes is used! Must be some crazy bug that makes such a huge overflow.
Then, I examined the memory more carefully, and it became clear that the stack space was filled with repeating patterns. Look: the sequence 0xFFFFFFFF, 0xFFFFFFFA, 0xA0006280, 0xA0005454:
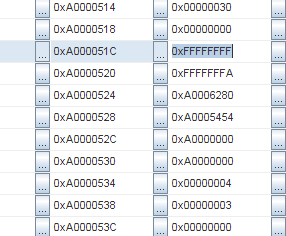
And the same sequence again:
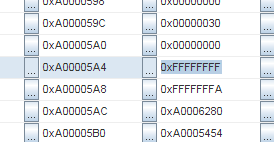
Addresses are 0xA000051C and 0xA00005A4. The difference is 136 bytes. Divided by 4 (the word size), it's 34 words.
Hmm, 34 words.. It's exactly the context size on MIPS! And the same pattern occurs again and again. So, the context seems saved several times in a row. But.. How could it happen?!
Well, unfortunately, it actually took quite some time to figure out the whole picture. First of all, I tried to examine the context that is saved on stack: among other things, there should be an address in program memory at which preempted thread should be resumed later. On PIC32, program flash is mapped into the region from 0x9D000000 to 0x9D007FFF, so, these addresses are easily distinguishable from other data. So I've picked addresses from the saved context data: one of them was 0x9D012C28. I looked at this address in the disassembly listing:
9D012C04 AD090000 SW T1, 0(T0) 9D012C08 8FA80008 LW T0, 8(SP) 9D012C0C 8FA9000C LW T1, 12(SP) 9D012C10 01000013 MTLO T0, 0 9D012C14 01200011 MTHI T1, 0 9D012C18 8FA10010 LW AT, 16(SP) 9D012C1C 8FA20014 LW V0, 20(SP) 9D012C20 8FA30018 LW V1, 24(SP) 9D012C24 8FA4001C LW A0, 28(SP) 9D012C28 8FA50020 LW A1, 32(SP) # <- Here it is 9D012C2C 8FA60024 LW A2, 36(SP) 9D012C30 8FA70028 LW A3, 40(SP) 9D012C34 8FA8002C LW T0, 44(SP) 9D012C38 8FA90030 LW T1, 48(SP) 9D012C3C 8FAA0034 LW T2, 52(SP) 9D012C40 8FAB0038 LW T3, 56(SP) 9D012C44 8FAC003C LW T4, 60(SP) 9D012C48 8FAD0040 LW T5, 64(SP) 9D012C4C 8FAE0044 LW T6, 68(SP) 9D012C50 8FAF0048 LW T7, 72(SP) 9D012C54 8FB0004C LW S0, 76(SP) 9D012C58 8FB10050 LW S1, 80(SP) 9D012C5C 8FB20054 LW S2, 84(SP) 9D012C60 8FB30058 LW S3, 88(SP) 9D012C64 8FB4005C LW S4, 92(SP) 9D012C68 8FB50060 LW S5, 96(SP) 9D012C6C 8FB60064 LW S6, 100(SP) 9D012C70 8FB70068 LW S7, 104(SP) 9D012C74 8FB8006C LW T8, 108(SP) 9D012C78 8FB90070 LW T9, 112(SP) 9D012C7C 8FBA0074 LW K0, 116(SP) 9D012C80 8FBB0078 LW K1, 120(SP) 9D012C84 8FBC007C LW GP, 124(SP) 9D012C88 8FBE0080 LW S8, 128(SP) 9D012C8C 8FBF0084 LW RA, 132(SP) 9D012C90 41606000 DI ZERO 9D012C94 000000C0 EHB 9D012C98 8FBA0000 LW K0, 0(SP) 9D012C9C 8FBB0004 LW K1, 4(SP) 9D012CA0 409B7000 MTC0 K1, EPC
This distinctive series of LW (Load Word) instructions from addresses relative to SP (Stack Pointer) is the context restore routine. It's clear now that the thread was interrupted while restoring context from stack. But how could it happen so many times in a row?! After all, I don't even have that many ISRs.
Previously, I just used TNKernel without clear understanding of how does it work, because it just worked. So I was even kind of afraid to dig deeply in the kernel. But this time, I had to.
Context switch in TNKernel for PIC32
We've already looked at the context switch in general, but now, let's re-visit this topic and add some TNKernel implementation details.
When the kernel decides to switch control from the thread A to the thread B, it does the following:
- Save all register values to stack (effectively, to the top of stack of thread A);
- Disable interrupts;
- Switch stack pointer to the top of stack of thread B;
- Switch current thread pointer to the descriptor of thread B;
- Perform some other kernel housekeeping;
- Enable interrupts;
- Restore all register values from stack (effectively, from the top of stack of thread B);
As you see, there is a short critical section while the kernel switches pointers: otherwise, there might be a situation when interrupt is triggered when stack pointer is already switched to thread B, but other things are still unchanged. This inconsistent data could easily lead to disaster.
Interrupts in TNKernel for PIC32
In TNKernel for PIC32, there are two types of interrupts:
- System interrupts: they are allowed to call kernel services, which can lead to the context switch after interrupt finishes. When this interrupt is triggered, full thread's context gets saved to stack before an ISR gains control;
- User interrupts: they are not allowed to call kernel services. Kernel performs no additional actions when such an interrupt is triggered.
Now, we're interested in System interrupts only. And TNKernel has a limitation for this kind of interrupts: all system interrupts in an application must have the same priority, so that such ISRs can't nest.
So, as a quick reminder, here's what happens when interrupt is triggered:
- Context of the current thread gets saved to the thread's stack;
- ISR does its business.
Now, an ISR is active, and stack memory usage is as follows:
As was already mentioned, this approach bumps our thread stack sizes: each thread stack should be able to hold the following things:
- Thread's own data;
- Thread's context (on MIPS, it's 34 words, i.e. 136 bytes);
- Data for worse-case ISR.
It's not a very nice thing to multiply stack space for ISRs by the number of threads, but, well, I can live with it.
Interrupt during context switch
Can you spot what happens when interrupt is triggered during context switch; i.e. when the current context is being currently saved to the thread's stack?
You might have already guessed: since the interrupts are not disabled during while context is being saved to stack, the context will be saved twice. Here we go:
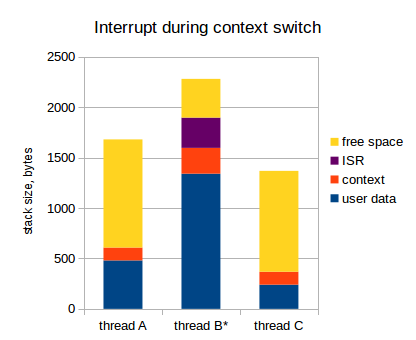
So, when kernel decides to switch from thread B to thread A, what happens is the following:
- Context is being saved on the stack of thread B;
- In between of this process, interrupt is triggered;
- Room for one more context is allocated on the stack of thread B, and context is saved there;
- ISR does its business.
- When ISR returned, the kernel picks next thread to run (it's thread A: remember, we wanted to switch there before interrupt has triggered)
- Disable interrupts;
- Switch stack pointer to the top of stack of thread A, perform other housekeeping;
- Enable interrupts;
- Restore all register values from stack (effectively, from the top of stack of thread A);
Here is what we get:
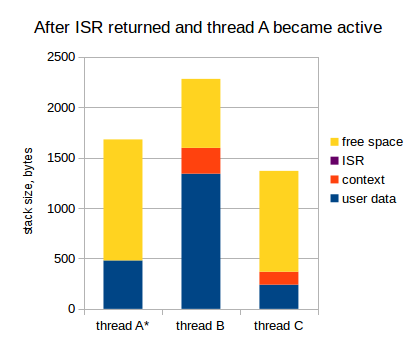
Look: the context is saved twice in the stack of thread B. But actually, it's not a disaster, if we haven't overflown the stack, since this double-saved context will be eliminated next time thread B gains control. For example, let's assume thread A goes to sleep, and the kernel switches back to thread B:
- Context is being saved on the stack of thread A;
- Disable interrupts;
- Switch stack pointer to the top of stack of thread B, perform other housekeeping;
- Enable interrupts;
- Restore context from the stack (of thread B).
At this point, we effectively returned to the moment when we were saving context before switching to thread A. So, we continue doing that:
- Finish saving context to the stack;
- Pick next thread to run (and now, this thread is already active: the thread B, so, no thread switch needed);
- Restore context back.
After that, thread B continues to operate just like nothing special happened:
As you see, it didn't actually break things, but we should make an important conclusion from this research: our assumption about things that each stack should be able to hold was wrong. At least, it must be able to hold 2 contexts, not a single context.
So, each thread's stack should be able to hold:
- Thread's own data;
- Thread's context (on MIPS, it's 34 words, i.e. 136 bytes);
- Second context. 136 bytes more;
- Data for worse-case ISR.
Oh dear.. 136 bytes more for each thread. Again, multiplied by the number of threads, for example, by 7 threads, this is almost 1 KB: more than 3% of total 32-KB.
Okay, I probably could live with it, but the final assumption is not, really, quite final. Things are even worse.
Going deeper
Let's explore the process of saving double context deeper: even after the research above, we still couldn't explain how it is possible for the context to be saved to stack more than 10 times.
Remember that TNKernel has a limitation that all system interrupts must have the same priority, so, when the second context is being saved to stack, if some other interrupt is triggered, it won't interrupt again, because current processor's interrupt level is set to the priority of interrupt already being handled.
But take a look at this again: ISR is already done, and we switched to the thread A:
At this point, current processor's interrupt level is lowered back, but the context is saved in the stack of thread B twice.
Have you guessed what's next?
Right: when we switch back to thread B, and while its context is being restored, there might happen one more interrupt. Consider:
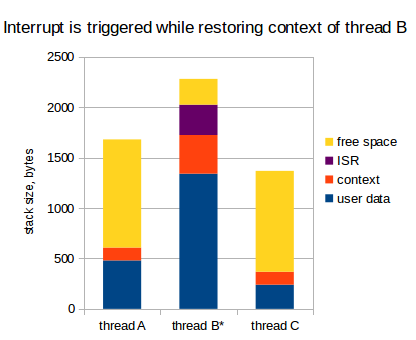
Yes, the context is already saved three times. And what is worse, that could even be the same interrupt: the same interrupt can save context multiple times.
So, if you're unlucky enough so that interrupt happens periodically, and exactly at the same rate at which tasks are switched back and forth, the context gets saved again and again, which, eventually, leads to stack overflow.
This was clearly overlooked by the author of TNKernel port for PIC32.
And this is what happened with my signal-measuring device: the ADC interrupt is triggered too often. What happens:
- ADC hardware measures next value and triggers an interrupt;
- My ADC ISR gets triggered, takes results from the ADC hardware, and sends a message to the high-priority thread which analyses ADC data;
- When ISR returns, the kernel switches control to ADC thread;
- The ADC thread quickly does its job and goes to sleep until next message is sent to it;
- The kernel switches back to whatever thread was executing when ADC interrupt was triggered. And while the context of this thread is restored, new ADC interrupt is triggered.
- Repeat.
Of course, it's my fault that ADC interrupts are generated too often, but the behaviour of the kernel is completely unacceptable. The right behaviour would be: my thread never gets control, until interrupt generation is stopped. Stack should not be polluted by lots of saved contexts, and when interrupt generation stopped, the system should continue to operate.
Well, and even if you we don't have such a periodic interrupts, anyway, there is a non-zero probability that multiple interrupts will save context 2 or more times. And embedded applications tend to work for weeks, months and years (for example, car alarm systems, trip computers, etc), so, as the working time approaches infinity, the probability of such a failure approaches 1. This is completely unacceptable, and obviously we can't leave things as they are.
Good: at least, now I know the reason of the failure. But how to solve it?
Probably the fastest dirty hack is to just disable interrupts while saving/restoring context. Yes, that would eliminate the problem, but it is a very bad solution: critical sections should be as short as possible, and disabling interrupts for such a long time is rarely a good idea.
A much better idea is to use separate stack for interrupts.
Trying to improve TNKernel
There is another port of TNKernel for PIC32 by Anders Montonen, and it uses separate interrupt stack. However, this port doesn't have some goodies that were implemented by Alex Borisov: convenient C macros for ISR definition, tn_sys_time_get(), and a couple of others.
So, I decided to fork it and have fun implementing what I want. Of course, in order to make such an important changes to the kernel, I had to figure out how it works under the hood. And the more I get into how TNKernel works, the less I like its code. It appears as a very hastily-written project: there is a lot of code duplication and a lot of inconsistency.
Examples of poor implementation
One entry point, one exit point
The most common example that happens across all TNKernel sources is code like the following:
int my_function(void) { tn_disable_interrupt(); //-- do something if (error()){ //-- do something tn_enable_interrupt(); return ERROR; } //-- do something tn_enable_interrupt(); return SUCCESS; }
If you have multiple return statements or, even more, if you have to perform some action before return, the code above is a recipe for disaster. We should rewrite it like this:
int my_function(void) { int rc = SUCCESS; tn_disable_interrupt(); if (error()){ rc = ERROR; } else { //-- so something } tn_enable_interrupt(); return rc; }
That way, for each new error handling, we should just add new else if block, and there's no need to manually re-enable interrupts. Let the compiler do the branching job for you.
Needless to say, I already found such bug in original TNKernel 2.7 code. The function tn_sys_tslice_ticks() looks as follows:
int tn_sys_tslice_ticks(int priority,int value) { TN_INTSAVE_DATA TN_CHECK_NON_INT_CONTEXT tn_disable_interrupt(); if(priority <= 0 || priority >= TN_NUM_PRIORITY-1 || value < 0 || value > MAX_TIME_SLICE) return TERR_WRONG_PARAM; tn_tslice_ticks[priority] = value; tn_enable_interrupt(); return TERR_NO_ERR; }
If you look closely, you can see that if wrong params were given, TERR_WRONG_PARAM is returned, and interrupts remain disabled. If we follow the one entry point, one exit point rule, this bug is much less likely to happen.
Don't repeat yourself
Original TNKernel 2.7 code has a lot of code duplication. So many similar things are done in several places just by copy-pasting the code.
If we have similar functions (like, tn_queue_send(), tn_queue_send_polling() and tn_queue_isend_polling()), the implementation is just copy-pasted, there's no effort to generalize things.
Mutexes have complicated algorithms for task priorities. It is implemented in inconsistent, messy manner, which leads to bugs.
Transitions between task states are done, again, in inconsistent copy-pasting manner. When we need to move task from, say, RUNNABLE state to the WAIT state, it's not enough to just clear one flag and set another one: we also need to remove it from whatever run queue the task is contained, probably find next task to run, then set reason of waiting, probably add to wait queue, set up timeout if specified, etc. In original TNKernel 2.7, there's no general mechanism to do this.
Meanwhile, the correct way is to create three functions for each state:
- to set the state;
- to clear the state;
- to test if the state active.
And then, when we need to move task from one state to another, we typically should just call two functions: one for clearing current state, and one for settine a new one. It is consistent.
As a result of the violation of the rule Don't repeat yourself, when we need to change something, we need to change it in several places. Needless to say, it is very error-prone practice.
Long story short, there are a lot of things in TNKernel that should have been implemented differently.
I decided to refactor it dramatically. To make sure I don't break anything, I started implementing unit tests for it. And very quickly I found out that original TNKernel was not tested at all: there are some nasty bugs in it!
For exact information about TNKernel problems, see Why reimplement TNKernel.
Meet TNeo
At some point, it became clear that what I'm doing is far beyond “refactoring”: there are some things in the TNKernel's API that I didn't like, so, I changed API slightly; and there are things that I was missing for too long: timers, software stack overflow control, events group connection, etc; so I implemented them.
It's not the TNKernel anymore. I was thinking about the new name for rather long time: I wanted to denote the direct relation to TNKernel, with something fresh and cool. So, the first name was TNeoKernel.
But, after some time, it has been naturally shortened to concise TNeo.
TNeo has a complete set of common RTOS features, plus some extras.
Many features are optional, so that if you don't need them you can configure the kernel as you wish and probably save memory or improve speed.
- Tasks, or threads: the most common feature for which the kernel is written in the first place;
- Mutexes: objects for shared resources protection:
- Recursive mutexes: optionally, mutexes allow nested locking;
- Mutex deadlock detection: if deadlock occurs, the kernel can notify you about this problem by calling arbitrary function;
- Semaphores: objects for tasks synchronization;
- Fixed-size memory blocks: simple and deterministic memory allocator;
- Event groups: objects containing various event bits that tasks may set, clear and wait for;
- Event group connection: extremely useful feature when you need to wait, say, for messages from multiple queues, or for other set of different events.
- Data queues: FIFO buffer of messages that tasks may send and receive;
- Timers: a tool to ask the kernel to call arbitrary function at a particular time in the future. The callback approach provides ultimate flexibility;
- Separate interrupt stack: interrupts use separate stack, this approach saves a lot of RAM;
- Software stack overflow check: extremely useful feature for architectures without hardware stack pointer limit;
- Dynamic tick: if there's nothing to do, don't even bother to manage system timer tick each fixed period of time;
- Profiler: allows you to know how much time each of your tasks was actually running, get maximum consecutive running time of it, and other relevant information.
It is hosted at GitHub: TNeo.
Currently, it is available for the following architectures:
- ARM Cortex-M cores: Cortex-M0/M0+/M1/M3/M4/M4F (supported toolchains: GCC, Keil RealView, clang, IAR)
- Microchip: PIC32MX/PIC24/dsPIC
Comprehensive documentation is available in two forms: html and pdf.
Now, let's peek at the implementation.
TNeo implementation
Of course it is impossible to cover the whole kernel implementation in this single article; instead, I'll try to remember what was unclear for me when I was struggling with it, and will focus on these things.
But first of all, I need to explain one internal data structure: the linked list.
Linked lists
Linked lists are the mechanism to chain some data entities together. This is the very popular data structure, and you're likely to be already familiar with it. However, for completeness, let's elaborate a bit.
TNeo uses linked lists heavily. To be more specific, it uses circular doubly-linked lists. The C structure looks as follows:
/** * Circular doubly linked list item, for internal kernel usage. */ struct TN_ListItem { /// /// pointer to previous item struct TN_ListItem *prev; /// /// pointer to next item struct TN_ListItem *next; };
It is defined in the file src/core/tn_list.c.
As you see, the structure contains two references to instances of the same structure: to the previous and to the next one.
We can create a chain of such structures, so that they are arranged as follows:
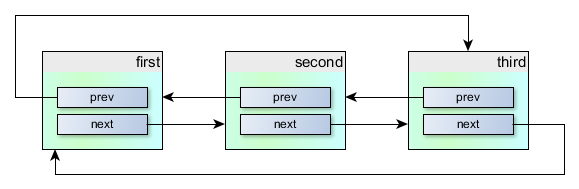
This is very nice, but probably not particularly useful. We'd like to have some payload in each object, don't we?
The approach is to embed struct TN_ListItem into any other structure we'd like to chain. For example, assume we have the structure MyBlock:
struct MyBlock { int field1; int field2; int field3; };
And we want to make these structures chainable. First of all, we need to embed struct TN_ListItem into it.
For this example, it would be logical to put it in the beginning of struct MyBlock, but just to emphasize that the structure can be anywhere inside, not only in the beginning, let's put it somewhere in the middle:
struct MyBlock { int field1; int field2; //-- say, embed it here. struct TN_ListItem list_item; int field3; };
Ok, nice. Now, create some instances of it:
//-- blocks to put in the list struct MyBlock block_first = { /* ... */ }; struct MyBlock block_second = { /* ... */ }; struct MyBlock block_third = { /* ... */ };
And now, one more crucial point: create a head of the list. A head is just a regular struct TN_ListItem, but not embedded anywhere:
//-- list head struct TN_ListItem my_blocks;
Now, we can create the following arrangement:
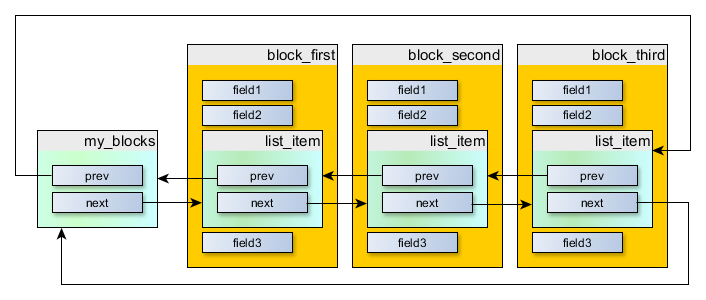
It can be created by code like this:
//-- Of course, it's not wise to always do that manually; // it's just for clarity. //-- list head references the first and the last items in our list my_blocks.next = &block_first.list_item; my_blocks.prev = &block_third.list_item; block_first.list_item.next = &block_second.list_item; block_first.list_item.prev = &my_blocks; block_second.list_item.next = &block_third.list_item; block_second.list_item.prev = &block_first.list_item; block_third.list_item.next = &my_blocks; block_third.list_item.prev = &block_second.list_item;
From the above, it's clear that we still have chains of TN_ListItems, not of MyBlocks. But the thing is: the offset from the beginning of MyBlock to its list_item is constant for all instances of MyBlock. So, if we have a pointer to TN_ListItem, and we know that this instance of it is embedded to MyBlock, we can subtract needed offset, and we get a pointer to MyBlock.
There is a special macro for that: container_of() (defined in the file src/core/internal/_tn_sys.h) :
#if !defined(container_of) /* given a pointer @ptr to the field @member embedded into type (usually * struct) @type, return pointer to the embedding instance of @type. */ #define container_of(ptr, type, member) \ ((type *)((char *)(ptr)-(char *)(&((type *)0)->member))) #endif
So given a pointer to TN_ListItem, we can easily get a pointer to wrapping MyBlock as follows:
struct TN_ListItem *p_list_item = /* ... */; struct MyBlock *p_my_block = container_of(p_list_item, struct MyBlock, list_item);
Now, we can iterate through all blocks in the list, like this:
//-- loop cursor struct TN_ListItem *p_cur; //-- iterate through all items in the list for (p_cur = my_blocks.next; p_cur != &my_blocks; p_cur = p_cur->next) { struct MyBlock *p_cur_block = container_of(p_cur, struct MyBlock, list_item); //-- now, p_cur_block points to the next block in the list }
This code works, but it is just a little bit too messy. It's much better to use special macro for iteration like this: _tn_list_for_each_entry(), defined in the file src/core/internal/_tn_list.h.
This way, we can just hide all the mess and iterate through the list of our MyBlock instances like this:
struct MyBlock *p_cur_block; _tn_list_for_each_entry( p_cur_block, struct MyBlock, &my_blocks, list_item ) { //-- now, p_cur_block points to the next block in the list }
So, it's very reliable way to create list of objects. And we can even include the same object in multiple lists: for this, of course, the wrapping structure should have multiple instances of TN_ListItem: for each list that the object can be included into.
I got asked on Hacker News about the implementation: why linked lists in TNeo are implemented exactly as they are, instead of something like this:
struct TN_ListItem { TN_ListItem *prev; TN_ListItem *next; void *data; //-- pointer to the payload object }
The question is interesting, so, I included the answer in the article:
TNeo never allocates memory from heap: it only operates on objects that are given as parameters to some kernel services. And this is really good: a great deal of embedded systems don't use heap at all (since heap behaviour is not deterministic enough).
So, for example, when task is going to wait for some mutex, the task is added to the list of waiting tasks of this mutex, and the complexity of this operation is O(1): that is, it is always done in constant time.
If we have an implementation with void *data;, we have two options:
- When adding new object to some linked list, TNeo should internally allocate this list item from heap (or from some preallocated pool);
- The client should allocate
TN_ListItems manually (in whatever way), and provide it to any kernel service that may need it.
Both options are unacceptable.
As I already mentioned, TNeo uses linked lists heavily:
- There is a list of all created tasks in the system: it can be useful to iterate all tasks, for example, to generate a profiler report;
- When task is runnable, it is added to the run queue for its priority (more on that later);
- When task is waiting for message from some queue, it is added to the queue's list of awaiting tasks;
- etc.
Actually, the same idea is used across the whole Linux Kernel. And a lot of helper macros were taken from Linux Kernel as they were, with just little adjustments: at least, we can't use GCC-specific extensions like typeof(), since TNeo compiles with not only GCC.
Tasks (threads)
Tasks, or threads, are the most important entities in the system: after all, this is the feature for which operating systems exist in the first place. In the context of TNeo and other real-time kernels, task is a subroutine that runs (seemingly) in parallel with other tasks.
Actually I prefer the term “thread”, but TNKernel uses “task”, so, I decided not to change it, in the name of compatibility. In this text, I use both terms interchangeably.
Each existing task in the system has its own descriptor: struct TN_Task, defined in the file src/core/tn_tasks.h. This structure is rather large.
First field of the task descriptor is a pointer to the top of the task's stack: stack_cur_pt. This fact is exploited by the assembler context switch routines: given the pointer to the task descriptor, we can easily dereference it, and resulting value will be the top of the task's stack.
Current task and next-to-run task
The kernel maintains two pointers: to the currently running task and to the needed task to run.
In src/core/internal/_tn_sys.h, we have:
/// task that is running now extern struct TN_Task *_tn_curr_run_task; /// task that should run as soon as possible (if it isn't equal to /// _tn_curr_run_task, context switch is needed) extern struct TN_Task *_tn_next_task_to_run;
As the comments suggest, if they are not equal, then context switch is needed.
Task priorities and run queues
Tasks can have different priorities. The maximum number of priorities available is determined by the processor's word size: for 16-bit MCUs there are max 16 priorities, and for 32-bit MCUs, there are max 32 priorities. This is needed to make kernel work as fast as possible, and to be honest, I never needed more than 5 priorities in my applications.
For each priority, there is a linked list of runnable (ready to run) tasks that belong to this priority.
In src/core/internal/_tn_sys.h, we have:
/// list of all ready to run (TN_TASK_STATE_RUNNABLE) tasks extern struct TN_ListItem _tn_tasks_ready_list[TN_PRIORITIES_CNT];
Where TN_PRIORITIES_CNT is the user-configurable value (of course, it can't be more than the maximum).
And task descriptor has the TN_ListItem to be included in some of these lists:
/** * Task */ struct TN_Task { /* ... */ /// queue is used to include task in ready/wait lists struct TN_ListItem task_queue; /* ... */ }
There is also a bitmask (a single word), where each bit set means that there are some runnable task with the corresponding priority:
/// bitmask of priorities with runnable tasks. /// lowest priority bit (1 << (TN_PRIORITIES_CNT - 1)) should always be set, /// since this priority is used by idle task which should be always runnable, /// by design. extern volatile unsigned int _tn_ready_to_run_bmp;
So when the kernel needs to determine next task to run, it executes architecture-specific find-first-set instruction on that word, and immediately gets maximum priority of all runnable tasks. It then takes the first task from the appropriate run queue (_tn_tasks_ready_list), and runs that task. That explains why maximum number of priorities depends on the word size.
Of course, when task enters or leaves the Runnable state, it maintains the corresponding bit in _tn_ready_to_run_bmp, which is a trivial thing to do. The whole thing works fast.
Task's context
Remember that when the task is not running at the moment, its context (all register values and program counter address) is saved to the stack. And stack_cur_pt in task descriptor points exactly at the top of the saved context.
For each supported architecture (MIPS, Cortex-M, etc), there is a well-defined context structure: how exactly are all these registers arranged in stack. When task is just created and is going to run, its stack space is populated with “initial” context, so that when it actually runs, this initial context gets restored. That way, each task starts in its isolated, clean environment.
Task states
The task could be in one of the following states:
- Runnable: Task is ready to run (it doesn't mean that it is running at the moment);
- Wait: Task is waiting for something;
- Suspended: Task is suspended (by some other task);
- Wait + Suspended: Task was previously waiting, and after this it was suspended;
- Dormant: Task isn't yet activated or it was terminated by tn_task_terminate(). The next time task is activated, any previous task data will be reset, and it will run in a brand new environment.
When task leaves or enters some state, there are certain things to be done. For example:
- When task leaves Dormant state, we should initialize its stack, so that task will run in a brand new environment;
- When task enters Runnable state, we need to add it to the run queue for corresponding priority and maintain
_tn_ready_to_run_bmp, so that the kernel will eventually schedule it; - When task leaves Runnable state, we need to remove it from its current run queue, maintain
_tn_ready_to_run_bmp, and if this was the currently running task, then we also need to find new task to run; - When task enters Wait state, we need to add it to corresponding wait queue (if necessary), and add to the timer queue if timeout was provided;
- When task leaves Wait state, we need to remove it from wait queue (if any), reset the timer if it is active;
- etc.
The thing is that when we, for example, leave Runnable state, we shouldn't care about the new state to set for task: Wait? Suspended? Dormant? It doesn't matter: whatever the case, we always should remove task from its current run queue and perform other things.
The consistent way to implement it is to have two functions for each state:
- To bring the task to this state;
- To get the task out of this state.
So, in the file src/core/tn_tasks.c we have the following functions:
void _tn_task_set_runnable(struct TN_Task * task) { /* ... */ } void _tn_task_clear_runnable(struct TN_Task * task) { /* ... */ } void _tn_task_set_waiting( struct TN_Task *task, struct TN_ListItem *wait_que, enum TN_WaitReason wait_reason, TN_TickCnt timeout ) { /* ... */ } void _tn_task_clear_waiting(struct TN_Task *task, enum TN_RCode wait_rc) { /* ... */ } //-- etc.
And when we need to move task from one state to another, it is usually as easy as:
_tn_task_clear_dormant(task); _tn_task_set_runnable(task);
And we can be sure that all necessary bookkeeping will be taken care of. Pretty neat, eh?
Task creation
There is an inevitable thing that task needs before it can run: the stack space. So, before task is created, we need to allocate an array to be used as a stack for this task, and pass it together with other things to tn_task_create().
The kernel sets top of the task's stack to the provided value, and puts task to Dormant state. It is not yet available to run. When the user calls tn_task_activate() (or if the flag TN_TASK_CREATE_OPT_START was given to tn_task_create()), kernel acts as follows:
- Remove task from Dormant state: as you already know, at this moment, task's stack gets initialized with brand new context;
- Put task to Runnable state: as you already know, at this moment, task is placed at the end of corresponding run queue (for task's priority).
Now, the kernel's scheduler will take care of this task, and run it when needed.
Let's take a look at how tasks get run.
Task running
The exact process of actual task running is, of course, architecture-dependent. But, as the general guide, kernel acts as follows:
- Get stack pointer from the task descriptor pointed to by
_tn_next_task_to_run, and set it as the current stack pointer; - Set currently running task (
_tn_curr_run_task) to_tn_next_task_to_run; - Load all register values from stack, one-by-one (remember that stack pointer was just set from the value stored in the descriptor of task that is going to run). As a part of these register values, there is a program address at which task execution should be resumed;
- Transfer control to task.
The actual way of transferring control to task (i.e. resuming task execution) is heavily architecture-dependent. For example, on MIPS, we should save the task's program counter to the register EPC (Exception Program Counter), and execute the instruction eret (return from exception). So, the kernel “tricks” a processor into behaving just like when it returns from a “regular” exception. After that, current PC (program counter) is set to the value stored in EPC, and, effectively, task is resumed.
Context switch
When the kernel stops execution of the current task, and switches to the next one, it is called a context switch. This routine always runs in the lowest priority ISR. So, when the context switch is needed, the kernel sets interrupt pending bit. If currently executing code is a user code (current interrupt priority is 0), then context switch routine (an ISR) gets called by the hardware immediately. If, however, this bit is set from some other ISR, then context switch ISR will be called later, when currently running ISR returns.
Of course, exact interrupt being used for context switch depends on the architecture. For example, on PIC32, the Core Software Interrupt 0 is used. Cortex-M chips have dedicated exception for context switches: PendSV.
When context switch ISR is called, it acts as follows:
- Save all register values to current task's stack, one-by-one. As a part of these register values, current task's program counter is saved, so that the task can be resumed later;
- When all register values are saved to stack, save stack pointer in the descriptor of the current task;
- Probably, perform on-context-switch handler (it is needed for profiler and for software stack overflow control, if either of these features is enabled);
- Now, perform exactly the same sequence as in previous section “Task running”.
Context switch is necessary when some high-priority task becomes Runnable, or when currently running task is put to Wait.
For example, let's imagine we have two tasks: low-priority Transmitter, and high-priority Receiver. Receiver tries to get message from the queue, and since queue is empty, it is put to Wait state. It is no more available for running, so, kernel proceeds to low-priority task Transmitter.
As you see from the diagram above, when low-priority Transmitter sends a message by calling tn_queue_send(), it gets preempted by the kernel in favour of high-priority Receiver immediately. So, by the time tn_queue_send() returns, a lot of things already happened:
- Context switched to Receiver;
- Receiver gets message and handles it;
- Receiver tries to get next message and is put to Wait;
- Context switched back to Transmitter.
This way, the system is very responsive: if you set right priorities for your tasks, events get handled very quickly.
Idle task
There is one special task in TNeo: the Idle task. It has the lowest priority (user tasks are unable to have that low priority), and it should always be runnable, so that _tn_ready_to_run_bmp always has at least one bit set: the bit of the lowest priority of Idle task. Obviously, kernel runs Idle task when there are no other runnable tasks.
User is allowed to implement a callback function that will be endlessly called from the Idle task. It can be used for various purposes:
- Processor sleep. When system has nothing to do, it often makes sense to bring processor to sleep, in order to cut the current. Of course, the application is responsible for setting some condition to wake up: typically, it's an interrupt.
- Calculation of system load. The easiest implementation is to just increment some variable in the idle task. The faster value grows, the less system is loaded.
Since Idle task should always be runnable, it is forbidden to call any kernel service from the callback that can put current task to wait.
Timers
The kernel needs to be aware of time flow. There are two schemes available: static tick and dynamic tick.
Static tick
Static tick is the easiest way to implement timeouts: there should be just some kind of hardware timer that generates interrupts periodically. Throughout this text, this timer is referred to as system timer. The period of this timer is determined by user (typically 1 ms, but user is free to set different value). In the ISR for this timer, it is only necessary to call the tn_tick_int_processing() function:
//-- example for PIC32, hardware timer 5 interrupt: tn_p32_soft_isr(_TIMER_5_VECTOR) { INTClearFlag(INT_T5); tn_tick_int_processing(); }
Each time tn_tick_int_processing() is called, we say that system tick is happened. Inside this function, kernel checks whether some timer is finished counting, and performs appropriate actions.
The easiest implementation of timers could be something like this: we have just a single list with all active timers, and at every system tick we should walk through all the timers in this list, and do the following with each timer:
- Decrement timeout by 1
- If new timeout is 0, then remove that timer from the list (i.e. make timer inactive), and fire the appropriate timer function.
This approach has drawbacks:
- We can't manage timers from the function called by timer. If we do so (say, if we start new timer), then the timer list gets modified. But we are currently iterating through this list, so, it's quite easy to mix things up.
- It is inefficient on rather large amount of timers and/or with large timeouts: we should iterate through all of them each system tick.
The latter is probably not so critical in the embedded world since large amount of timers is unlikely there; whereas the former is actually notable.
So, different approach was applied. The main idea is taken from the mainline Linux Kernel source, but the implementation was simplified much because (1) embedded systems have much less resources, and (2) the kernel doesn't need to scale as well as Linux does. You can read about Linux timers implementation in the book “Linux Device Drivers”, 3rd edition:
- Time, Delays, and Deferred Work
- Kernel Timers
- The Implementation of Kernel Timers
This book is freely available at http://lwn.net/Kernel/LDD3/.
So, TNeo's implementation:
We have configurable value N that is a power of two, typical values are 4, 8 or 16.
If the timer expires in the next 1 to (N - 1) system ticks, it is added to one of the N lists (the so-called “tick” lists) devoted to short-range timers using the least significant bits of the timeout value. If it expires farther in the future, it is added to the “generic” list.
Each N-th system tick, all the timers from “generic” list are walked through, and the following is performed with each timer:
- timeout value decremented by N
- if resulting timeout is less than N, timer is moved to the appropriate “tick” list.
At every system tick, all the timers from current “tick” list are fired unconditionally. This is an efficient and nice solution.
The attentive reader may want to ask why do we use (N - 1) “tick” lists if we actually have N lists. That's because, again, we want to be able to modify timers from the timer function. If we use N lists, and user wants to add new timer with timeout equal to N, then new timer will be added to the same list which is iterated through at the moment, and things will be mixed up.
If we use (N - 1) lists, we are guaranteed that new timers can't be added to the current “tick” list while we are iterating through it (although timer can be deleted from that list, but it's ok).
The N in the TNeo is configured by the compile-time option TN_TICK_LISTS_CNT.
But for some applications that spend a lot of time doing nothing this could be far from perfect: instead of being constantly in the power-saving mode while there's nothing to do, the CPU needs to wake up regularly. So, dynamic tick scheme was implemented:
Dynamic tick
The general idea is that there should be no useless calls to tn_tick_int_processing(). If the kernel needs to wake up after 100 system ticks, then, tn_tick_int_processing() should be called exactly after 100 periods of system tick (but external asynchronous events still can happen and re-schedule that, of course).
To this end, the kernel should be able to communicate with the application:
- To schedule next call to
tn_tick_int_processing()after N ticks; - To ask what time is now (i.e. get current system ticks count).
So, when dynamic tick mode is active (TN_DYNAMIC_TICK is set to 1), user should provide these callbacks to the kernel. The actual implementation of scheduling next call to tn_tick_int_processing() is completely MCU-dependent (even on the same architecture, there are lots of different MCUs, which have different peripherals, etc), so, it's up to the application to implement these callbacks correctly.
System start
In order for the system to run normally, the kernel needs for the following:
- Stack space for Idle task;
- Stack space for interrupts;
- Idle task callback function;
- Some user task(s) to run.
So, user application should allocate stack arrays for Idle task and for interrupts, provide Idle callback function (it may be empty), and provide special callback function that will create at least one (and typically just one) user task. This will be the first task that runs, and in my applications I name it 'task_init' or 'task_conf'. Obviously, it performs some initializations.
In main(), user should:
- Disable system interrupts by calling
tn_arch_int_dis(); - Perform some essential CPU configuration, such as oscillator settings, etc;
- Setup system timer interrupt (from which
tn_tick_int_processing()gets called); - Call
tn_sys_start(), providing all necessary information: pointers to stacks, their sizes and your callback functions.
The kernel acts as follows:
- Initialize run queues (
_tn_tasks_ready_list), and other internal kernel things; - Create and activate Idle task (
_tn_next_task_to_rungets set to Idle task); - Call user's callback function, in which user initial task is created and activated (
_tn_next_task_to_rungets set to user task); - Call architecture-dependent function
_tn_arch_sys_start(), which initializes scheduler interrupt, and performs first context switch to the task pointed to by_tn_next_task_to_run.
At this point, system operates normally: user initial task gets executed. Typically, it does the following:
- Perform initialization of various on-board peripherals (displays, flash memory chips, or whatever);
- Initialize software modules used by application;
- Create all the rest of user tasks (everything is already initialized, so they can proceed with their jobs);
More implementation details
Well, I guess I just have to stop at some point, at least for now: I can't explain each and every detail of the implementation in this article, which is quite long already.
I tried to touch upon the most interesting topics that are needed to get the big picture; for others, you can easily examine the source code, which I very much tried to make really good. Source code is are available: use it!
If you have any questions, feel free to ask in the comments.
Unit tests
Usually, when people talk about unit tests, they mean tests that run on the host computer. But, sadly, embedded C compilers often have their own bugs, so I decided to test the kernel directly in the hardware. This way, I can be sure that the kernel 100% works in my device.
Here is a brief overview of how they're implemented:
There is a high-priority task like “test director”, which creates worker tasks as well as various kernel objects (queues, mutexes, etc), and then orders to workers, like:
- Task A, you lock the mutex M1
- Task B, you lock the mutex M1
- Task C, you lock the mutex M1
- Task A, you delete the mutex M1
After each step it waits for workers to complete their job, and then checks if things are as expected: task states, task priorities, last return values of services, various properties of objects, etc.
Detailed log is written to the UART. Typically, for each step, the following is written:
- verbatim comment is written,
- director writes what does it do,
- each worker writes what does it do,
- director checks things and writes detailed report.
Of course there is a mechanism for writing such scenarios. Here is a part of code that specifies the sequence with locking and deleting mutex explained above:
TNT_TEST_COMMENT("A locks M1"); TNT_ITEM__SEND_CMD_MUTEX(TNT_TASK__A, MUTEX_LOCK, TNT_MUTEX__1); TNT_ITEM__WAIT_AND_CHECK_DIFF( TNT_CHECK__MUTEX(TNT_MUTEX__1, HOLDER, TNT_TASK__A); TNT_CHECK__MUTEX(TNT_MUTEX__1, LOCK_CNT, 1); TNT_CHECK__TASK(TNT_TASK__A, LAST_RETVAL, TN_RC_OK); ); TNT_TEST_COMMENT("B tries to lock M1 -> B blocks, A has priority of B"); TNT_ITEM__SEND_CMD_MUTEX(TNT_TASK__B, MUTEX_LOCK, TNT_MUTEX__1); TNT_ITEM__WAIT_AND_CHECK_DIFF( TNT_CHECK__TASK(TNT_TASK__B, LAST_RETVAL, TWORKER_MAN__LAST_RETVAL__UNKNOWN); TNT_CHECK__TASK(TNT_TASK__B, WAIT_REASON, TSK_WAIT_REASON_MUTEX_I); TNT_CHECK__TASK(TNT_TASK__A, PRIORITY, priority_task_b); ); TNT_TEST_COMMENT("C tries to lock M1 -> C blocks, A has priority of C"); TNT_ITEM__SEND_CMD_MUTEX(TNT_TASK__C, MUTEX_LOCK, TNT_MUTEX__1); TNT_ITEM__WAIT_AND_CHECK_DIFF( TNT_CHECK__TASK(TNT_TASK__C, LAST_RETVAL, TWORKER_MAN__LAST_RETVAL__UNKNOWN); TNT_CHECK__TASK(TNT_TASK__C, WAIT_REASON, TSK_WAIT_REASON_MUTEX_I); TNT_CHECK__TASK(TNT_TASK__A, PRIORITY, priority_task_c); ); TNT_TEST_COMMENT("A deleted M1 -> B and C become runnable and have retval TN_RC_DELETED, A has its base priority"); TNT_ITEM__SEND_CMD_MUTEX(TNT_TASK__A, MUTEX_DELETE, TNT_MUTEX__1); TNT_ITEM__WAIT_AND_CHECK_DIFF( TNT_CHECK__TASK(TNT_TASK__B, LAST_RETVAL, TN_RC_DELETED); TNT_CHECK__TASK(TNT_TASK__C, LAST_RETVAL, TN_RC_DELETED); TNT_CHECK__TASK(TNT_TASK__B, WAIT_REASON, TSK_WAIT_REASON_DQUE_WRECEIVE); TNT_CHECK__TASK(TNT_TASK__C, WAIT_REASON, TSK_WAIT_REASON_DQUE_WRECEIVE); TNT_CHECK__TASK(TNT_TASK__A, PRIORITY, priority_task_a); TNT_CHECK__MUTEX(TNT_MUTEX__1, HOLDER, TNT_TASK__NONE); TNT_CHECK__MUTEX(TNT_MUTEX__1, LOCK_CNT, 0); TNT_CHECK__MUTEX(TNT_MUTEX__1, EXISTS, 0); );
And here is the appropriate part of log that is echoed to the UART:
//-- A locks M1 (line 404 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task A: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task A]: locking mutex (0xa0004c40).. [I]: [Task A]: mutex (0xa0004c40) locked [I]: [Task A]: waiting for command.. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=6 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- B tries to lock M1 -> B blocks, A has priority of B (line 413 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task B: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task B]: locking mutex (0xa0004c40).. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- C tries to lock M1 -> B blocks, A has priority of C (line 422 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task C: lock mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task C]: locking mutex (0xa0004c40).. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=MUTEX_I (as expected), last_retval=NOT-YET-RECEIVED (as expected) [I]: * Mutex M1: holder=A (as expected), lock_cnt=1 (as expected), exists=yes (as expected) //-- A deleted M1 -> B and C become runnable and have retval TN_RC_DELETED, A has its base priority (line 431 in ../source/appl/appl_tntest/appl_tntest_mutex.c) [I]: tnt_item_proceed():2101: ----- Command to task A: delete mutex M1 (0xa0004c40) [I]: tnt_item_proceed():2160: Wait 80 ticks [I]: [Task A]: deleting mutex (0xa0004c40).. [I]: [Task C]: mutex (0xa0004c40) locking failed with err=-8 [I]: [Task C]: waiting for command.. [I]: [Task B]: mutex (0xa0004c40) locking failed with err=-8 [I]: [Task B]: waiting for command.. [I]: [Task A]: mutex (0xa0004c40) deleted [I]: [Task A]: waiting for command.. [I]: tnt_item_proceed():2178: Checking: [I]: * Task A: priority=6 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_OK (as expected) [I]: * Task B: priority=5 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_DELETED (as expected) [I]: * Task C: priority=4 (as expected), wait_reason=DQUE_WRECEIVE (as expected), last_retval=TN_RC_DELETED (as expected) [I]: * Mutex M1: holder=NONE (as expected), lock_cnt=0 (as expected), exists=no (as expected)
If something goes wrong, there would be no “as expected”, but an error and explanation what we expected and what we have. Tests halted.
I did my best to model nearly all possible situations within the each single subsystem (such as mutexes, queues, etc), including various situations with suspended tasks, deleted tasks, deleted objects, and the like. It helps a lot to keep the kernel really stable.
Final words
How does TNeo handle interrupts
In general, there are two approaches to handle interrupts in an OS: Unified and Segmented. Consider reading a great article on these: RTOS Interrupt Architectures.
In the very short, RTOS with Segmented interrupt architecture can be written so that it never disables interrupts. On the other hand, it adds an overhead to the context switching, and it's harder to write an application for Segmented architecture, since we should care about top/bottom halves of ISRs.
It's easier to write an application for a RTOS with Unified interrupt architecture, and context switches are faster, but such a RTOS has to disable interrupts globally in its critical sections. You'll find all the details in the aforementioned article.
TNeo uses Unified interrupt architecture. It disables interrupts for short periods of time in almost all kernel services. I find it quite fine for my particular applications: they would never suffer from disabling interrupts for, say, 100 instructions. For example, on 40 MHz, 100 instructions take 2.5 us. In my applications, events don't happen that often. But anyway, you should be aware of this.
Let me quote the last paragraph of the article:
While both Segmented and Unified Interrupt Architecture RTOSes enable deterministic real-time management of an embedded system, there are significant differences between them with regard to the efficiency and simplicity of the resulting system. Segmented RTOSes can accurately claim that they never disable interrupts within system services. However, in order to achieve this, they instead must delay application threads, introducing a possibly worse consequence. The segmented approach also adds measurable overhead to the context switch process, and complicates application development. In the end, a unified interrupt architecture RTOS demonstrates clear advantages for use in real-time embedded systems development.
From my experience, the last sentence holds true for the majority of applications. However, there might be some applications where disabling interrupts is something to be strictly avoided. Consider that point carefully before using TNeo or any other RTOS with Unified interrupts architecture.
Why not just use FreeRTOS
Well, there are some reasons.
First, I don't like their policy: the license states that it's forbidden to compare FreeRTOS to any other kernel! Just look at the latest paragraph of the FreeRTOS licence:
FreeRTOS may not be used for any competitive or comparative purpose, including the publication of any form of run time or compile time metric, without the express permission of Real Time Engineers Ltd. (this is the norm within the industry and is intended to ensure information accuracy).
As far as I know, they added this clause after a very old discussion on Microchip forum, where people have shown metrics of different kernels, and these metrics are unfavourable for FreeRTOS. The author of FreeRTOS claimed that metrics are wrong, but, funnily enough, he failed to show the “correct” ones.
So, if I write some kernel that leaves FreeRTOS behind in some aspect, I'm not able to write about it. What the what, guys?
I don't like that kind of things.
By the way, a long time ago, when my colleagues suggested to use TNKernel, they were claiming that TNKernel is much faster than FreeRTOS. After I've implemented TNeo, of course I've done some benchmarks, but sadly I can't publish the results due to FreeRTOS license.
Second, I don't like its source code either. Probably I'm being too idealistic, but for me, the real-time kernel is a kind of special project, and I want it to be as close to an ideal as possible.
Yes, it's time now for you to check out TNeo code on GitHub and argue why it sucks. Probably that will help me to make the kernel even better!
Third, I wanted to have more or less drop-in replacement for TNKernel, so that I can easily port old applications to the new kernel.
And last but not least, it was a great fun to work on real-time kernel!
Still, FreeRTOS has a hard-to-beat advantage: it is available for lots of architectures. Luckily, I don't need that many.
Where TNeo is used
Now, I've ported to TNeo all existing projects that were built with TNKernel: trip computers, battery chargers, etc. It works flawlessly.
I presented the kernel at the Microchip MASTERS 2014 (the yearly training conference), and the Head of Research and Development of the car alarm company StarLine LLC asked me to port the kernel to Cortex-M chips. Now it's done, and the kernel is now used in their latest products.
Documentation and downloads
So, TNeo is a well-formed and carefully tested preemptive real-time kernel for 16- and 32-bits MCUs. It is compact and fast.
The project is hosted at GitHub.
Currently, it is available for the following architectures:
- ARM Cortex-M cores: Cortex-M0/M0+/M1/M3/M4/M4F (supported toolchains: GCC, Keil RealView, clang, IAR)
- Microchip: PIC32MX/PIC24/dsPIC
Comprehensive documentation is available in two forms: html and pdf.
You might as well be interested in:
Discuss on
 Reddit, or right here:
Reddit, or right here:
Discussion
Great work! and thanks for the write up :)
Thanks for your feedback!
Did you look at RTEMS (https://www.rtems.org/) ? Free as in GPL (mostly; see https://www.rtems.org/license), multi-threaded, hard realtime OS. Actively maintained/used by NASA, among others. RTEMS 4.10 is currently in orbit as the OS on the main flight computers of the four satellites of the Magnetospheric MultiScale mission.
I used RTEMS as the OS in embedded development for medical devices circa 2006. It was a joy to work with: performant in small footprints, POSIX API interface, did what needed doing and then got out of the way. At that time it didn't have a USB stack, which eventually turned into a problem, but I think that's since been addressed.
Thanks for the comment.
Haven't looked closely yet, but from what I know, its POSIX compatibility makes it much larger than little beasts like FreeRTOS or TNeo. For example, in minimal kernel configuration, this little sample on TNeo takes 7.6 kB of ROM.
Anyway, I'll look into RTEMS more closely, thanks for mentioning it.
Thank you for this exceptionally interesting and well-written “story” of why and how you built your own RTOS kernel. Your excitement shines through the page.
These two lines demonstrate the curious heart, spirit, attitude of a great developer!
JTurner, thank you very much for such a positive feedback!
This is a fantastic write up. But do you think your new OS has now fewer bugs than the previous OS ? I mean this question in the most literal way.
Thanks for the feedback.
Yes, I'm sure. Previous OS (TNKernel) was not tested at all, since I found (and fixed) a lot of bugs in it (see Bugs of TNKernel 2.7.
Now, TNeo has very thorough tests that cover each subsystem in a very detailed way, and they really help me to keep the kernel stable. There were already a couple of situations when my new improvements actually broken some things, and tests quickly revealed that for me. Wonderful.
But I hoped that I already written that in the article. Was I that unclear?
Very nice work!
Thanks for your feedback!
Hi..
Maybe is a stupid question but… why using separate stack for interrupts could prevent to save the context more then one time? I mean, it can avoid the duplication of space used by ISR, but if one interrupt occurs when the context is being saved to stack it will continue to save a new context, right?
Thanks :)
Hi, thanks for the question!
You're right: if some interrupt occurs when the context is being saved to stack, new context will be saved, but this new context will be saved on the interrupt stack this time, not the stack of the thread being interrupted.
And when ISR returns, the context gets restored from the interrupt's stack, then it continues to save on thread's stack, and then, eventually, kernel switches to new thread.
So, we can say for sure: stack of each thread should be able to store exactly one context, not more.
Thank you, great effort and wonderful article, very few people able axplain so complex things so masterfully !
Peter, thank you very much, it's always nice to get so positive feedback!
Thank you for a great article!
I wrote a small “embedded” kernel starting in 1989 and found many of the ideas and thoughts I had then here too.
So my system uses a unified interrupt architecture, with a separate system stack for the interrupts (and system calls as well). It has signals, semaphores, message passing and streams, processes and threads (the former with memory mapping changes, the latter in the same memory map, where available).
I/O performance is sluggish though, as streams work byte-wise, and interrupt latency is hindered by the context switch code and the usually 1 MHz system clock… But looking at the context switch code, I have to say the 6502 has two advantages: very reduced set of registers to save, and an “RTI” instruction that returns into user mode and at the same time re-enables interrupts (by restoring the processor status from the stack).
Maybe you like it, here's the homepage http://www.6502.org/users/andre/osa/index.html and here is an introduction to version 1 (without threads): http://www.6502.org/users/andre/osa/oa1.html
André
thank you for your nice works.
I have a question for you. which tool used for drawing linked-list shapes? They are perfect!
thank you…
gerbay
Thanks for the comment!
The tool to draw these diagrams is yEd. Not that I'm absolutely satisfied with it, but nevertheless, it's awesome!
Dmitry Frank,
I have some Olimex 2106 development boards and i would like to experiment TNeo on these boards.
Do you hava a port for the ARM7TDM1 used on this boards. I'm new to the subject and i don't have the knowledge to make a port.
Thanks,
Israel
Hi Israel!
I've already replied via email, but will write here as well.
Thanks for your interest in TNeo. Unfortunately, there's currently no port of TNeo for ARM7TDM1, and I have totally no free time these days to invent it. So I guess you have to resort to different kernel then, even though it makes me sad to say this to you. :)
Thanks again!
Hi, Dmitriy. Round-robin algorithm (TNeo) dont work! Strings 204 - … in tn_sys.c dont switch current task. (Keil, STM32L053, Cortex-M0)
(Keil, STM32L053, Cortex-M0)
Hi. Thanks for the bugreport; at the moment I don't have a chance to try the fix for real, so I've created a separate branch, here's a fixed _round_robin_manage(), could you please verify that it solves the problem for you?
It is working! Thank you. Add it in release.
But it not good to use time_slice number as round robin switch.
If i set time_slice = 2, for example, i get the tasks running 3 sys_ticks.
This can be corrected by replacing a sign > on >= in string #203 (tn_sys.c):
if (_tn_curr_run_task→tslice_count >= _tn_tslice_ticks[priority]){
…
Best regards, Dmitriy.
Hi Dmitry,
Just to let you know, my last fix introduced a new (rather severe) bug in round-robin, here's the fixing commit: https://github.com/dimonomid/tneo/commit/f44acf63a227336e467b60bdf2c8c17cfb9ec50b
I also applied your fix of the off-by-one error, thanks for reporting that!
To implement separate stack to all ISR do you have a wrapper function with the customer handler pointer as a parameter or what? I am just reading this article for better understanding your ideas and concepts.
Thanks,
Sam.
Excellent article ! i enjoyed every minutes of it. :):) Kudos to you! I like your spirit. /thierry
A well-written, comprehensive article that brought back memories. I (and many others) did this same thing as far as 40 years ago. Solved the same problems, including the unending OS vs. no-OS debate. (Back then, no-OS usually won.) I'm always amused by how each generation of programmer needs to reinvent the wheel. I see that tendancy in every aspect of current software development, from embedded to web and every interface between. But I really thought embedded OSs were a long-settled issue.
There are a few, proven, small footprint IOT OSs available these days. RIOT popped up on HN just yesterday; it looks promising and seems to have a comprehensive ecosystem for testing, integration and portability, which yours probably doesn't. Not sure why someone would risk writing their own, given the complexity, which you so nicely illustrate. For the fun of it I guess, and the chance to learn something (which is mostly why we did it back then).
But I'm glad to no longer be involved in that work. You kids knock yourselves out. I'll write the history books.
Thanks for the amazing article, Dimitry! I've learnt a lot from it.
The reason I'm writing is because I've checked you claim regarding the FreeRTOS license, but according to this 29th Nov 2017 article, it is MIT licensed: https://aws.amazon.com/blogs/opensource/announcing-freertos-kernel-v10/
I've checked in archive.org that even on 1st Jul 2018 that license file you linked was still talking about that “comparative purpose” prohibition, but today 3rd Feb 2019, it's indeed just a simple MIT license.
It doesn't invalidate the rest of your reservations, but still puts things into a very different light, I guess.
Btw, I was looking into this topic, because I was wondering if there is a way to write an alternative to the https://qmk.fm/ keyboard firmware in some higher level and more interactive language/system than C, like Forth or Lisp and indeed there are quite a lot of alternatives with decent microcontroller support, eg:
Have you considered implementing a kernel in such higher level languages?
The appeal for me for doing so would be to get away from the constraints of the C ecosystem, which is pretty much a lock-in and imposes a lot of complexity-tax on users if they want to marry it with some higher-level language…
By constraints, I mean things like you don't have namespaces, hence everything is prefixed with TN_. You only have the string-based, C preprocessor to create macros, which are consequently not obvious how to unit-test. I can understand how these things migth become second nature or a blind spot if you are mostly programming in C, but I think higher-level languages can offer more clarity with a lot less code, which should make it easier for others to understand and use it and reduce the amount of habitat provided for software bugs. :)
Hi Dmitry,
Just a word to say that this is really a great post.
I learnt alot.
Thanks
Maurycy
Thanks Maurycy!
Hi Dmitry, great work. It was very intersting to read. By the way do you know the works of Miro Samek (state-machine.com and especially his book PSiCC2)? Due to his book I changed my approach to development of embeded systems. Now for some small system I dont use OS at all. But I understand that it's a must for more complicated systems.
Very nice effort and explanations, thank you for having taken the time to write this all so nicely and with diagrams ! :) I am into retro computing (with Atari ST computers, 8MHz 68000-based) and writting a music sequencer where a lot of things have to happen, and this is all very insightful!
hi,Dmitry Frank! I'm a fan of TNeo. I just learned TNeo.Tested a lot of experimental code, such as:
—– Mutexes struct TN_Mutex mutex_1; —– Sem struct TN_Sem sem_1;
tn_mutex_create( &mutex_1, TN_MUTEX_PROT_INHERIT, 0);tn_sem_create( &sem_1, 1, 2 );– c task void task_c_body(void *par) { printf(“New task c is OK!\n”); for(;;) { tn_mutex_lock(&mutex_1, 1); arrm[1]=200; tn_mutex_unlock(&mutex_1); printf(“c_arrm[1]=%d\n”,arrm[1]); tn_task_sleep(50); enum TN_RCode rc = tn_sem_wait(&sem_1, 1); if (rc == TN_RC_OK) printf(“wait_SEM_OK,sem_1.count:%d\n”,sem_1.count); } } – d task void task_d_body(void *par) {
printf("New task d is OK!\n");for(;;) { tn_mutex_lock(&mutex_1, 1); arrm[1]=100; tn_mutex_unlock(&mutex_1);printf("d_arrm[1]=%d\n",arrm[1]); tn_task_sleep(50);}
They work OK! Now I wonder how Dynamic tick does it? Can you give a sample of STM32? Like my test above, thanks! !
I'm really a newbie with little experience.
Great creator! Now I wonder how Dynamic tick does it? Same sample based on STM32: struct TN_Mutex mutex_1; struct TN_Sem sem_1; tn_mutex_create( &mutex_1, TN_MUTEX_PROT_INHERIT, 0); tn_sem_create( &sem_1, 1, 2 ); void task_c_body(void *par) { printf("New task c is OK!\n"); for(;;) { tn_mutex_lock(&mutex_1, 1); arrm[1]=200; tn_mutex_unlock(&mutex_1); printf("c_arrm[1]=%d\n",arrm[1]); tn_task_sleep(50); enum TN_RCode rc = tn_sem_wait(&sem_1, 1); if (rc == TN_RC_OK) printf("wait_SEM_OK,sem_1.count:%d\n",sem_1.count); } } void task_d_body(void *par) { printf("New task d is OK!\n"); for(;;) { tn_mutex_lock(&mutex_1, 1); arrm[1]=100; tn_mutex_unlock(&mutex_1); printf("d_arrm[1]=%d\n",arrm[1]); tn_task_sleep(50); tn_sem_signal(&sem_1); } }Holy moly, thanks for the great educational write up! Congrats on all your success.
Hey Oz, thanks for the comment, glad you liked it!
Fantastic write up, thank you!
I used TNKernel in a small project about 15 or so years ago, I liked it at the time, but I never used it again, can't remember why.
TNeo just popped up on my RADAR, maybe I will use it again now that you have sorted it out :)
Thanks, Shaun
Thanks Shaun, happy to hear you liked it